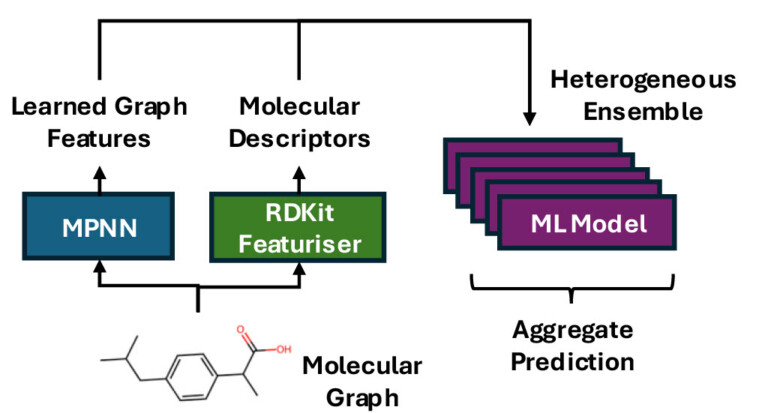
Looking beyond statistics: How do I determine whether a QSAR model will add value to my project?
Good statistics don’t guarantee good applicability. Performance metrics will tell you how well a QSAR model predicts known data, but they don’t tell you whether it will add practical value…