Designing and optimising new drugs involves balancing multiple objectives, including target activity, metabolic stability, absorption, safety, and more. Predictive models assist in screening compounds against these criteria before committing to expensive synthesis and testing. The more properties you can confidently predict, the better you can prioritise which compounds to progress.
In StarDrop 8, we’ve added five new models and enhanced two existing models to help you build more complete and accurate profiles of your compound library.
What’s new: Expand your ADME coverage with five new models
HLM CLint Category: Your first stop for metabolic assessment
Our new intrinsic clearance model for human liver microsomes (HLM CLint) has been one of our most-requested models.
Why clearance matters
CLint is a measure of the liver’s inherent ability to metabolise a compound (primarily by cytochrome P450s), independent of blood flow limitations. It reflects how efficiently liver enzymes can process a drug, and is a key factor in determining metabolic stability and half-life. CLint is usually expressed in mL/min and can be derived from in vitro systems such as human liver microsomes or hepatocytes. Lower CLint values indicate metabolic stability, while higher values suggest rapid clearance.
Our CLint model functions as an effective initial screening tool for your compound library. Running it first provides an immediate overview of metabolic stability across your entire series, enabling you to prioritise compounds based on the results. You can then focus your more computationally intensive metabolism calculations on compounds with favourable clearance.
How the HLM CLint model works
We opted for HLM over the alternatives as it’s the most common experimental assay and has high-quality publicly available data. Current QSAR approaches are not yet able to reliably predict in vivoclearance.
Our classification model groups compounds into three categories:
Stable: CLint < 20 µL/min/mL
Moderate: 20 µL/min/mL ≤ CLint < 300 µL/min/mL
Unstable: ≥ 300 µL/min/mL
We trained, validated, and tested the model on over 5,200 compounds curated from the work of Esaki et al., achieving a weighted Cohen’s Kappa of 0.64 (read more about evaluating classification model performance with Cohen’s Kappa and how we know our models work). Most importantly, the model did not misclassify stable compounds as unstable or vice versa in our training and test sets. This is important for making informed and confident decisions.
Integration with our Metabolism module
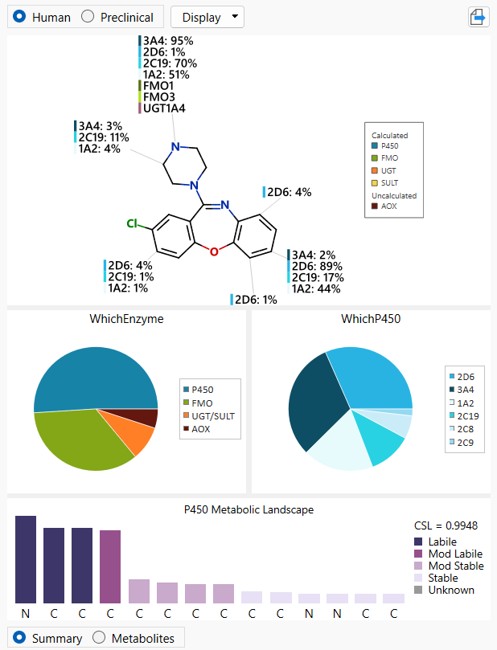
The new HLM CLint model also complements the StarDrop Metabolism module. For example, the WhichP450 model within the module can predict which P450 isoform is most likely to metabolise your compound, helping to identify potential drug-drug interaction risks or concerns regarding genetic polymorphisms.
The P450 regioselectivity models predict the metabolic hotspots within your compounds. Suppose you know a particular position is a potential site of metabolism. In that case, you can make targeted modifications, such as adding blocking groups, introducing fluorine, or using bioisosteric replacements, to improve stability. You’re not just identifying the problem; you’re getting actionable information to solve it.
In combination with StarDrop’s Metabolism module, our new HLM CLint model gives a complete picture of metabolic stability.
The efflux transporter P-glycoprotein (P-gp) is a common cause of issues with drug absorption and distribution. If your compound binds to P-gp, it’s important to understand how it will interact:
A substrate will be actively transported out of cells.
An inhibitor may prevent the efflux of a co-administered drug, leading to potential drug-drug interactions.
Why P-gp matters
P-gp is highly promiscuous and is expressed in both the intestine and the blood-brain barrier (BBB).
In the intestine, P-gp can reduce oral bioavailability by pumping absorbed compounds back into the gut lumen.
At the BBB, it can reduce CNS penetration by actively removing compounds from the brain.
A wide variety of chemically unrelated compounds can bind to P-gp, acting as substrates or inhibitors. As such, P-gp interaction profiling should be included in any drug design and optimisation strategy.
How the new P-gp inhibition model works
The P-gp inhibition category model classifies whether a compound will be an inhibitor or a non-inhibitor. It has been added alongside the existing P-gp substrate model in StarDrop, providing a more complete interaction profile of your compounds.
We curated our dataset from the work of Broccatelli et al. and Przybylak et al., obtaining approximately 1,300 datapoints with a good balance between inhibitors and non-inhibitors. The dataset covers the chemical space of known drug compounds very well.
We used a validation set approach to test different machine learning methods and optimise hyperparameters. This approach paid off, as we achieved an exceptionally high Kappa value of 0.8 on our independent test set.
Three more models for safety and absorption
hERG pKi: A more reliable cardiac safety predictor
The hERG potassium channel plays a key role in cardiac repolarisation. Inhibition of this channel can prolong the QT interval on an electrocardiogram, potentially leading to life-threatening arrhythmias.
Based on user feedback, we’ve replaced our hERG pIC50 model with a more reliable pKi model that measures binding affinity to the hERG channel. Higher pKi values correspond to stronger binding and, consequently, greater potential for hERG-related cardiotoxicity. These values are widely used in computational modelling to identify and prioritise compounds with acceptable cardiac safety profiles in early-stage drug discovery.
The data for our hERG model was obtained from PubChem. Trained, validated, and tested on approximately 2,000 compounds, it achieves an R² of 0.74 and an RMSE of 0.54 log units on an independent test set, meaning you can screen for hERG liabilities across more diverse scaffolds with greater confidence.
Caco-2 cell monolayers are widely used as an in vitro model of human intestinal epithelium to estimate the passive and active permeability of orally administered compounds. Understanding intestinal permeability is essential for predicting oral bioavailability and optimising pharmacokinetics.
Our new Caco-2 model predicts the apparent permeability coefficient (Papp) as a continuous value. Trained, validated, and tested on approximately 1,300 compounds with good drug-like chemical space coverage, validated on 150 compounds, and tested on an additional 150 compounds, it achieves an R² of 0.77 and an RMSE of 0.35 log units on the independent test set. For chemists working on oral drugs, this helps assess whether compounds will achieve adequate absorption early in the design process.
The Ames test is a widely used biological assay that determines if a compound is likely to induce genetic mutations in specific strains of Salmonella typhimurium. This property is critical in early drug discovery and chemical safety evaluation, as mutagenic compounds may pose carcinogenic risks.
Our Ames model is a binary classifier (mutagenic or non-mutagenic), trained, validated, and tested on around 7000 compounds (one of our largest training sets). It achieves a Cohen’s kappa of 0.61. The large, diverse training set means good applicability across chemical scaffolds. It works well in conjunction with our Derek Nexus module for comprehensive genotoxicity assessment.
What’s improved: Broader chemical space, more confident predictions
We’ve enhanced our blood-brain barrier (BBB) category model and human intestinal absorption (HIA) category model with expanded training sets.
The statistical performance on independent test sets remains broadly similar to the legacy models (HIA kappa: 0.78, BBB kappa: 0.66), but the significantly larger and more diverse training sets provide the real advantage: better coverage of drug-like chemical space and more realistic performance assessments. With our new models, you can make predictions with greater confidence and more reliable classification boundaries across a larger variety of molecular scaffolds.
For existing users: We’ve retained legacy models for users with established MPO profiles. Your existing projects continue to work. However, we’ve updated sample scoring profiles to use the new models and recommend using them for new projects.
Putting it all together: Practical implications for your projects
The models are ready to use and integrate with StarDrop’s data analysis and visualisation capabilities to inform your compound design strategy.
The Glowing Molecule™ lets you instantly visualise which structural features are driving each prediction. For example, with the HLM CLint model, you can see which parts of your molecule are contributing to metabolic instability and use that information to guide modifications.
For multi-parameter optimisation, you can combine new models with existing ADME QSAR predictions and your own experimental data to build scoring profiles that weight properties based on your project needs. A CNS drug might prioritise BBB penetration and metabolic stability whilst managing hERG risk. A peripheral drug might prioritise HIA and Caco-2 permeability whilst avoiding BBB penetration to prevent CNS side effects. Importantly, probabilistic scoring accounts for prediction uncertainty, giving you a realistic comparison between compounds.
If you need models tailored to specific chemistry or targets, you can build custom QSAR models using Auto-Modeller™ and use them alongside these pre-built models for a comprehensive prediction strategy.
Ready to trial StarDrop?
Simply complete the form now for a free personalised demo and see how StarDrop fits your unique research needs.
Mario is a Principal Scientist at Optibrium with deep expertise in computational chemistry. He holds a PhD in Natural Sciences from Tallinn University of Technology, where he focused on advanced modelling approaches.
Since joining Optibrium in 2017, Mario has driven key research and development in metabolism prediction, creating next-generation models that bring together quantum mechanics and machine learning to support more confident discovery decisions.