Machine Learning 101: How to train your first QSAR model
My hope is that these posts will be of interest to people who want to understand more of the nuts…

The regular (non-hyper) parameters of an ML model are the numbers that it adjusts during the training process. For example, if you’re fitting a linear regression model, the parameters are the slope of the line with respect to each input feature and the offset, giving a total of N+1 parameters for N input variables.
For most ML models, we never care about the actual parameter values. In fact, for complex models like neural networks, there are frequently so many parameters that it is almost impossible to work out what any of the parameters actually do. The largest LLMs (large language models) have hundreds of billions of parameters, so studying their individual behaviour is extremely difficult and largely pointless.
In contrast, hyperparameters are not trained during the fitting process. They are set in advance, most commonly by the scientist defining the model. These include things like the number of decision trees in a random forest, the number of layers in a deep neural network, or the learning rate of the model (how quickly parameters are adjusted) during training.
As hyperparameters determine the fundamental structure of the model, they can have an enormous impact on how it performs in practice. A model that is too complex, with too many degrees of freedom, is likely to over-fit the training data and underperform on the test data. On the other hand, a model that isn’t flexible enough will under-fit the training data and still underperform on the test data.
There are also practical considerations which impact hyperparameter choices, such as computing cost. Training a billion-parameter neural network is an extremely expensive experiment, so if a similar level of performance can be achieved with a leaner model, you might want to prioritise that instead.
If you want to achieve the best possible model performance, you need to have the optimal set of hyperparameters. Unfortunately, it is impossible to determine this in advance except in very simple cases (and some heuristics like big models will do better on big datasets), and you will need to experiment with different parameter combinations. This process is known as hyperparameter optimisation and can take various forms, from manually trying a few different ideas that you think could work to large-scale automated hyperparameter searches. As you will have to re-train the model each time you evaluate a set of hyperparameters, this can be very computationally expensive for larger models. Therefore, there’s a strong incentive to make this process as efficient as possible.
As a quick example, I’ll demonstrate how to optimise a gradient boosting model (essentially a slightly fancier random forest) on the Caco-2 dataset from Wang et. al. that I’ve used in previous articles on ‘How to train your first QSAR model’ and ‘How to build your first neural network’.
Firstly, we can get a baseline understanding for how well the model performs without any optimisation by running it with the default hyperparameters:
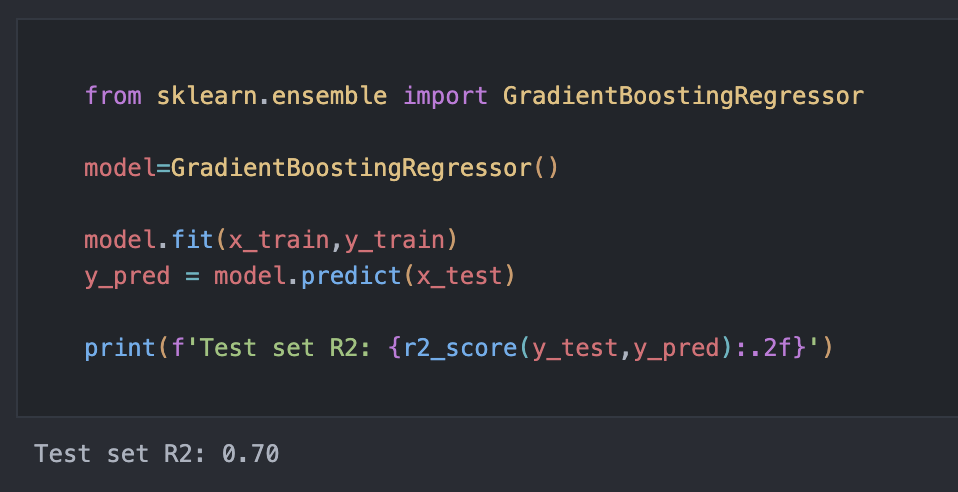
Notably, this is the same as we found with our random forest QSAR model, and very slightly better than the 0.688 from our neural network. The lack of differentiation between models indicates that the hyperparameters of all three models are likely reasonably good for this problem already (the default SKLearn parameters for the random forest and gradient boost, and the simple three-layer network I used for the NN). In fact, I intended to use the random forest model for this example initially, but I found no improvement in its performance with optimisation, implying that the default hyperparameters are already pretty much optimal for this problem.
Next, we need a strategy to optimise the hyperparameters. I’m going to use the Optuna library, which provides a range of efficient algorithms for automated hyperparameter optimisation. To use it, we need to define an objective function, which takes an Optuna trial object as an argument and returns a numerical value. We specify the hyperparameters that the trial should suggest, and Optuna will refine them to maximise the returned value:
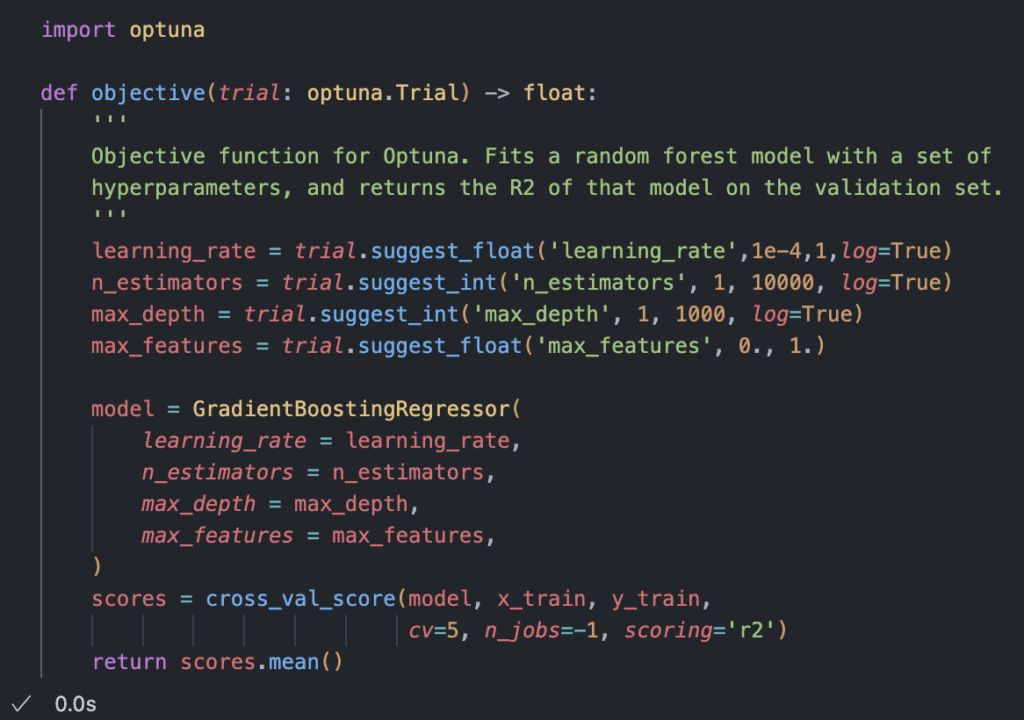
An important thing to note here is that we are not evaluating the model performance on the test set during hyperparameter optimisation, instead we’re using cross validation to evaluate the model on different splits of the training set. The reason for this is simple – some hyperparameter combinations will tend to give better results on the test set just by chance, effectively over-fitting the test data, and this would give us a false impression of how good the model actually is. To take this to an extreme, imagine a “model” that is just a random number generator with a seed hyperparameter. If you evaluate enough of these random generations on the test set, you’ll get one that gives a good R-squared, but it won’t have any predictive value whatsoever.
Running the optimisation is now trivial. We give Optuna the objective function, tell it to maximise the returned value, and off it goes:
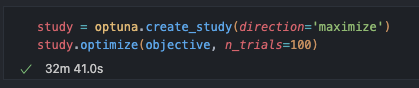
It runs N trials (in this case 100) with different hyperparameter combinations, using Bayesian optimisation to efficiently explore the hyperparameter space and homing in on the best combinations.
However, this is not a quick process, even with advanced search strategies. Running on my MacBook Pro, this takes 30-45 minutes for 100 trials. This is because it must fit 100 models for each of the 5 different cross validation splits, and some of those models (the ones with larger numbers of trees) will take 30s or longer to train. With larger models, larger datasets, and more complex problems, this can be extremely expensive and require dedicated compute clusters.
At the very largest scale, it becomes almost impossible to run hyperparameter optimisation at all. It takes months to train the current generation of large language models once, costing tens or even hundreds of millions of dollars. Training these models hundreds of times to identify the optimal hyperparameters would be ruinously expensive. To work around this, smaller-scale models are typically used to develop heuristics for the most effective hyperparameter combinations, and these lessons are then used to make a best guess at what will work well when scaled up.
Going back to our model, we can now evaluate how the best hyperparameter combination from the study performs on the test set:
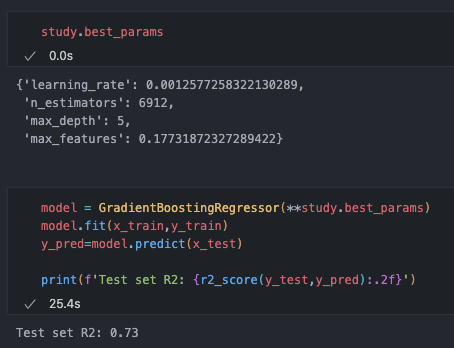
As you can see, all that effort has improved our R-squared value by just 0.03. We’ve also ended up with a much larger, slower model, taking 25s to train compared to just 1.5s for the default hyperparameters. The main reason for this is the number of estimators (decision trees) in the ensemble, which is 100 by default and 6812 for our optimised model.
Optuna also provides a set of visualisation tools so that we can see how the different hyperparameters behave. For example, we can see that the learning rate and number of estimators are the most important hyperparameters:
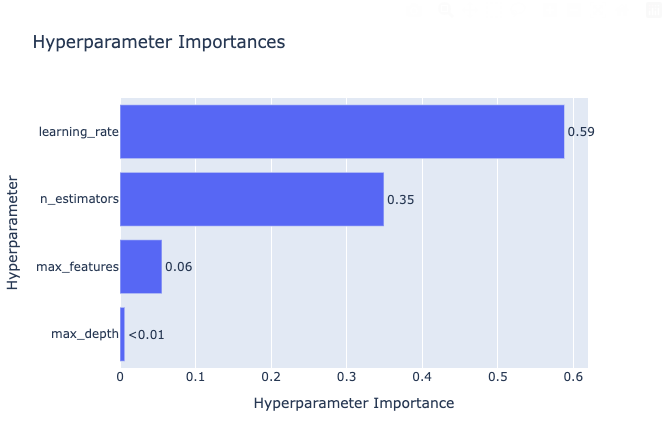
If we look at the behaviour of the learning rate more closely, we see that the R-squared (objective value on the graph) peaks around a rate of 0.001:
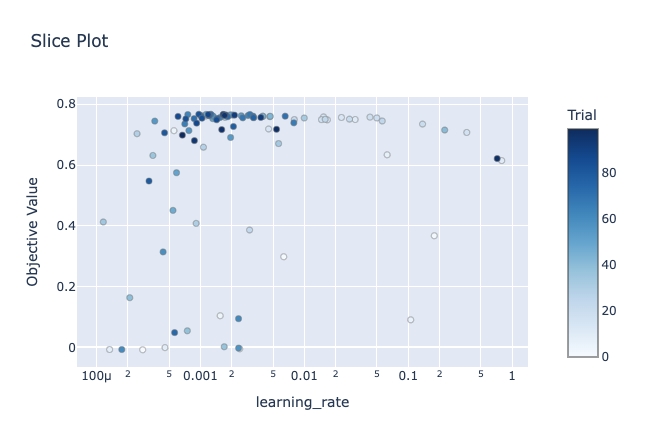
As a result, although we have produced our best model yet on this dataset, we’ve only made a relatively small improvement using a time-consuming process. This was not an optimal setup for hyperparameter optimisation, as our initial model was already quite good.
However, his example does do a good job of illustrating the trade-off between model performance and time/expense: for some use cases, a good model now may be worth more than a ‘perfect’ model and a large bill in a few days’ time.
Hyperparameter optimisation is supported by our StarDrop™ Auto-Modeller module, that allows users to build and validate robust, tailored QSAR models directly within StarDrop’s molecular design and data visualisation environment. It’s also a support feature within our dedicated platform for AI-powered drug discovery, Cerella, which informs decision making around the best compounds and most valuable experiments for your project. If you’d like to know the specifics of how this is done, don’t hesitate to get in touch.
Michael is a Principal AI Scientist at Optibrium, applying advanced AI techniques to accelerate drug discovery and improve decision-making. With a Ph.D. in Astronomy and Astrophysics from the University of Cambridge, he brings a data-driven approach to solving complex scientific challenges. Michael is also a thought leader, contributing to discussions on the impact of AI in pharmaceutical research.

My hope is that these posts will be of interest to people who want to understand more of the nuts…
What are neural networks? Neural networks (NNs) in various forms are very common nowadays, and specific architectures are used for…
