Is AI improving drug discovery?
Is AI-guided drug discovery faster and cheaper? The evidence for this is, by definition, anecdotal. No one runs the same…

Is AI-guided drug discovery faster and cheaper? The evidence for this is, by definition, anecdotal. No one runs the same…
What’s the purpose of a predictive model? What’s the value of predictive models for drug discovery? Most of the undergraduate…

The role of generative chemistry in drug discovery A key difficulty in finding new drugs is the sheer size of…

Discover which metabolite prediction software is best for your needs in this comprehensive guide from Optibrium. Compare top tools like Meteor Nexus, MetaSite, and StarDrop to make informed decisions for drug metabolism prediction

How number of users affect drug discovery software costs The number of people who need access to the platform is…

Introduction The emergence of resistance and increased stringency of regulatory requirements have created a need for new agrochemicals. The long…

To guide drug design, it’s important to understand the likely ADME and physicochemical properties of your compounds at an early…

Develop advanced MPO strategies and target the right compounds, faster.
We’re diving back into our favourite subject: multi-parameter optimisation.

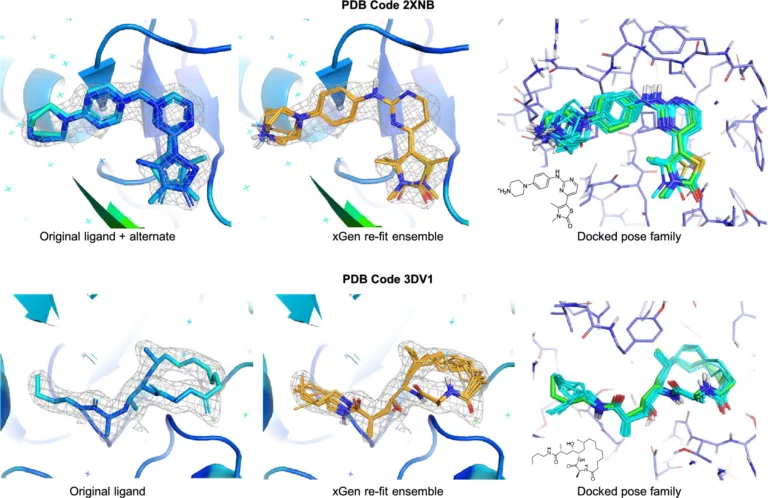
In this paper, we describe an extended benchmark for non-cognate docking of macrocyclic ligands, and the superior performance of Surflex-Dock…

Successful drugs require a delicate balance of many properties, such as potency, ADME and toxicity, to meet a project’s therapeutic objective. To make decisions about compound progression and assay selection, the available data must be assessed against project-specific criteria. However, the data on which we base our decisions often come from different sources and can vary in quality, so how can we use this information to make confident decisions? In addition, how can we be sure that the criteria we’re using are the most appropriate?

Generative molecular design provides new exciting avenues of chemical space exploration. But how can we use these methods effectively to assess many optimisation strategies and find the compounds destined for success in our projects?
Join Dr Matt Segall and Dr Michael Parker as they explore state-of-the-art generative chemistry, and discuss the importance of an augmented intelligence approach for successful discovery.

This peer-reviewed paper in Xenobiotica describes a new method to determine the most likely experimentally-observed routes of metabolism and metabolites based on our WhichP450™, regioselectivity and new WhichEnzyme™ model.
This paper describes a model to predict whether a particular site on a molecule will be metabolised by cytosolic sulfotransferase enzymes (SULTs).
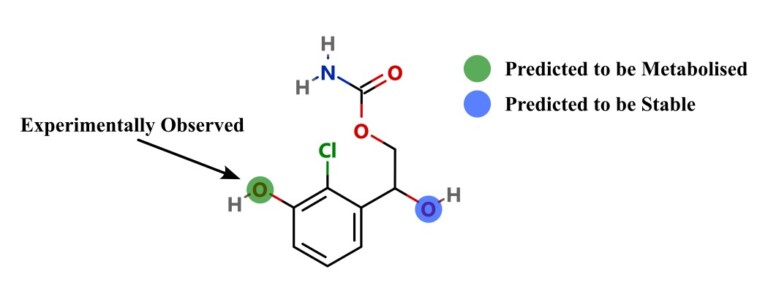
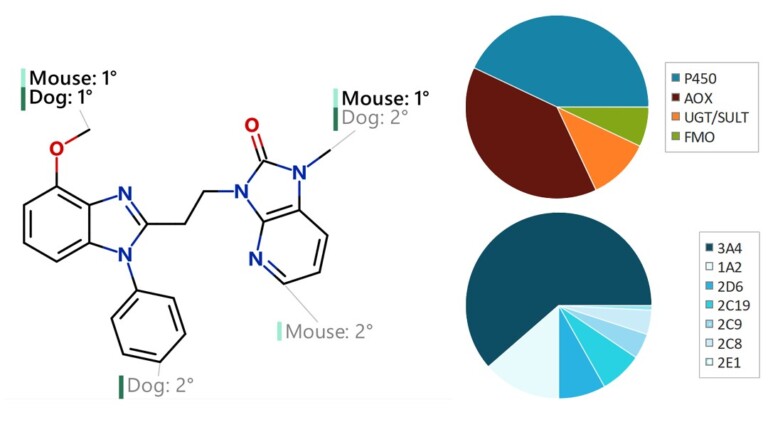
This paper describes the prediction of the regioselectivity of metabolism by AOs, FMOs and UGTs for humans and CYPs for three preclinical species.
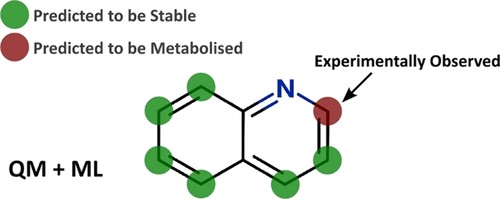
In this webinar, Jeff Blaney (Senior Director of Discovery Chemistry, Genentech), Darren Green (Head of Cheminformatics & Data Science, GlaxoSmithKline), Julian Levell (Head of Discovery, New Equilibrium Biosciences), Matthew Segall (CEO, Optibrium) discuss the state of AI in early drug discovery from hit to preclinical candidate and share their experiences with and expectations of AI, including predictive modelling, synthesis prediction, and generative chemistry. Hear about the successes of AI drug discovery and an outlook on what AI needs to achieve to really transform the industry.

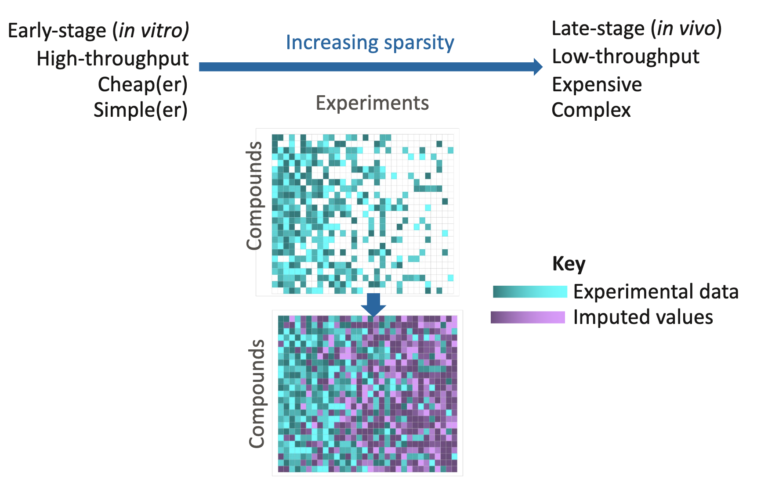
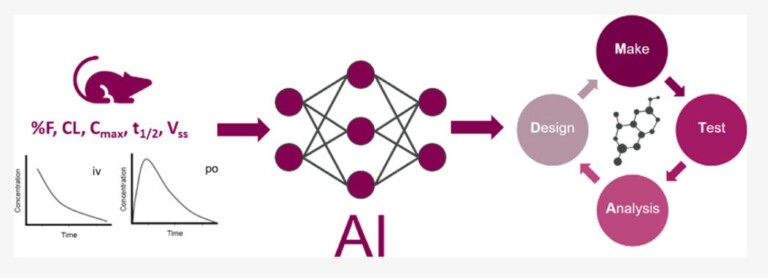
This article is a collaboration with Intellegens, the University of Cambridge and AstraZeneca. It provides a proof-of-concept study in which Cerella™ is used to predict rat in vivo pharmacokinetic (PK) parameters and concentration–time PK profiles.
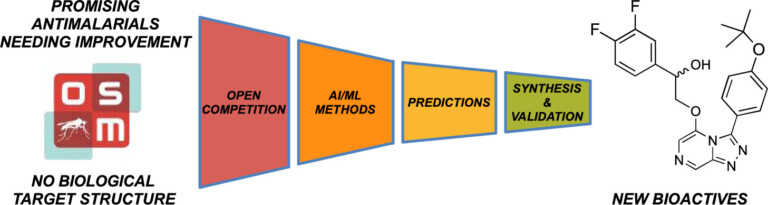
In this study, we identified a new antimalarial with an unusual structure – the only compound in the competition to be proven active, opening up new chemistry for exploration.