This Open Access paper outlines practical applications of deep imputation on large-scale drug discovery data. It compares deep learning to traditional QSAR methods. Find out more about deep imputation by visiting our Cerella webpage.
Summary
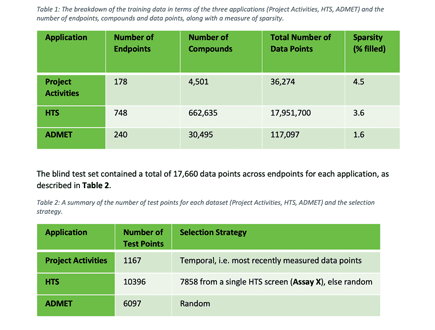
Accurately predicting biological properties of potential drug compounds is challenging. This is particularly due to limited amounts of quality data; experiments are time-consuming, expensive and can inevitably include some errors and uncertainties.
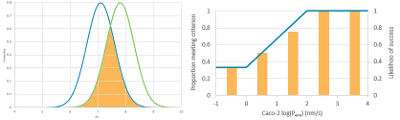
This article outlines the deep learning imputation methods underpinning our Cerella platform, applied to large data sets. It demonstrates significant improvements over commonplace quantitative structure-activity relationship (QSAR) machine learning models, in several use cases. These include compiling target activity data from a range of drug discovery projects, assessing ADME properties and looking at model performance on early-stage sparse, noisy high-throughput screening data.
Citation details
B. W. J. Irwin, T. M. Whitehead, S. Rowland, S. Y. Mahmoud, G. J. Conduit, M. D. Segall, Applied AI Lett., 2021 2(3) p. e31
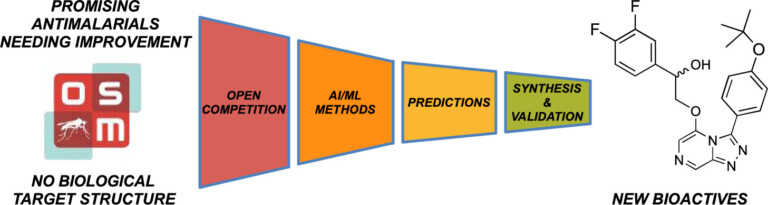
In this study, we identified a new antimalarial with an unusual structure – the only compound in the competition to be proven active, opening up new chemistry for exploration.
In this ebook we demonstrate our deployable AI discovery platform, Cerella™. Browse real-world stories of success from our collaborations with AstraZeneca, Genetech, Takeda Pharmaceuticals, Constellation Pharmaceuticals and many more.