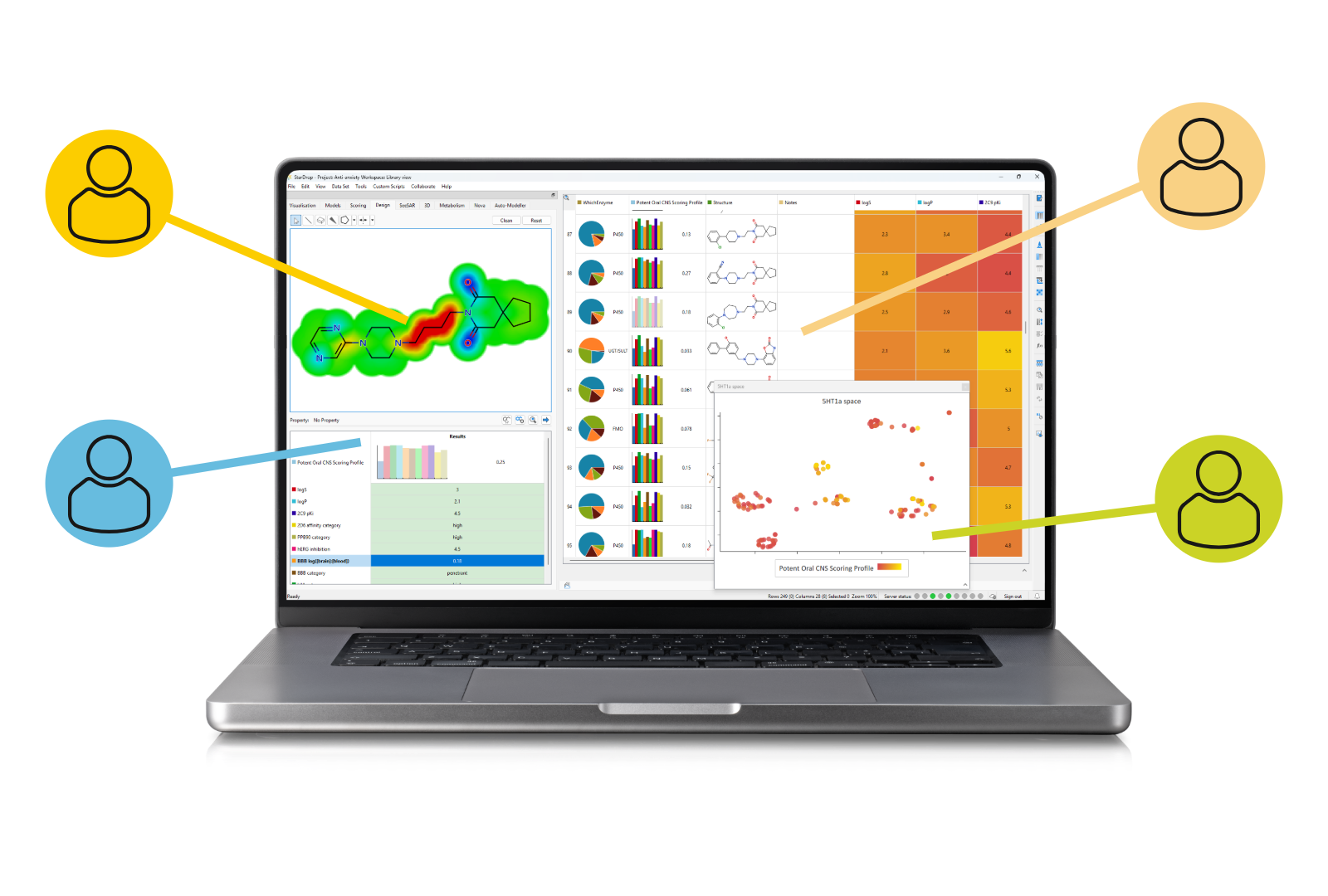
Partnering with CROs, academic labs, and specialist consultants allows you to pool expertise, accelerate timelines, and often progress candidates more quickly and cost-effectively than working alone.
To do this efficiently, you need to share enough data so that your partners can do meaningful work, whilst protecting proprietary information. Therefore, every collaboration introduces the same dilemma:
How do you share the right data with the right people, without exposing your IP?
The collaboration challenge: Where generic tools fall short
Several collaboration platforms have been designed to support molecule design and optimisation. However, certain limitations create friction:
“Real-time” that isn’t: Some platforms use report snapshots rather than live shared data. If you need to keep recreating reports to ensure you have current information, you never truly know whether you’re looking at the latest picture. This means you’ll just end up making copies of data, creating storage bloat and audit complexity.
Coarse access controls: All-or-nothing access means you either over-share proprietary information or under-share critical context, creating bottlenecks through repeated clarifications.
Performance limitations: We’re now accessing bigger compound libraries than ever before. If a platform restricts you to sharing only a few hundred compounds, you’re forced to work around the system for larger data sets, undermining the purpose of collaborative software.
Vendor lock-in: Discovery teams rely on a mix of in-house and third-party tools, including registration systems, databases, ELNs, and modelling tools. Platforms that only support integrations with tools from a single vendor force you to choose between your existing infrastructure and effective collaboration.
As a result, teams risk wasted effort on deprioritised compounds, delays waiting for data compilation, and the tension between protecting IP and enabling efficient collaboration.
StarDrop 8: Real-time collaboration where you’re in control
StarDrop 8‘s collaboration framework and flexible data set sharing controls address this challenge directly, enabling teams to work with external partners in real-time while maintaining complete control over sensitive information.
True real-time synchronisation: You always see the latest data automatically. When your CRO updates a synthesis status or adds results, your internal team sees it immediately, with no report generation, no snapshots, and no manual refreshing.
Granular data control: Share specific compounds and selected data fields with each external partner, whilst protecting internal metadata, design rationale, and registration information. You know exactly what each CRO sees.
Performance at scale: Whether you’re sharing dozens of compounds or thousands, StarDrop handles the volume without compromising speed or performance.
Vendor-neutral integration: StarDrop is designed to fit in with tools you already rely on, with built-in integrations to corporate registration systems and databases. Your collaboration workflows integrate with your established infrastructure
A CRO partnership in practice
Let’s consider a practical scenario:
Your internal team designs and triages compounds in StarDrop, while your CRO partner handles synthesis and bioassay work. Results return as assay data, which your team evaluates alongside ADME predictions to prioritise the next synthesis round.
Here’s how StarDrop makes this workflow straightforward:
Project setup: Built for controlled collaboration
Every collaboration begins with a StarDrop Project, set up by a project owner within your organisation. This owner adds members to the project, including:
Internal colleagues who need full access
External CRO collaborators, who require only limited, role-specific access
Granting the right access for the right role
Your internal team sees the complete picture, with StarDrop automatically capturing all the essential metadata for decision-making. Every added compound is assigned a unique ID. StarDrop also captures the creation date, the user who added the compound, and its source (e.g., from file, Designer, or Inspyra). It can be configured to
regularly check back with your registration system to learn if any of the virtual molecules have been registered, and if so, return their corporate ID.
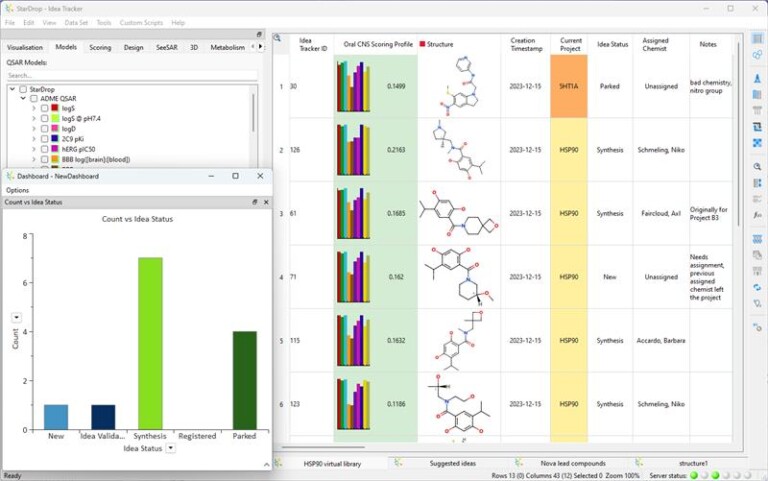
You can also further configure your StarDrop data sets in the project with customisable fields to capture project-specific categories (e.g., New, sent to CRO, in synthesis, verified, registered, parked, etc.), assigned personnel, compound notes or internal commentary.
Your CRO partners will only have access to the data sets you share with them. They can also be restricted from having access to any automatic idea tracking. This means that while they can potentially add notes and annotations to the data sets they use (if you need them to do so), they won’t be able to access or update any internal annotations, corporate IDs, design rationale, audit trails, internal compound lifecycle status, or registration-linked metadata. However, compounds they add to data sets will still be tracked as soon as any of your internal team members access them.
As a result, your CRO partners get exactly what they need to do their work, but nothing that compromises IP or internal processes.
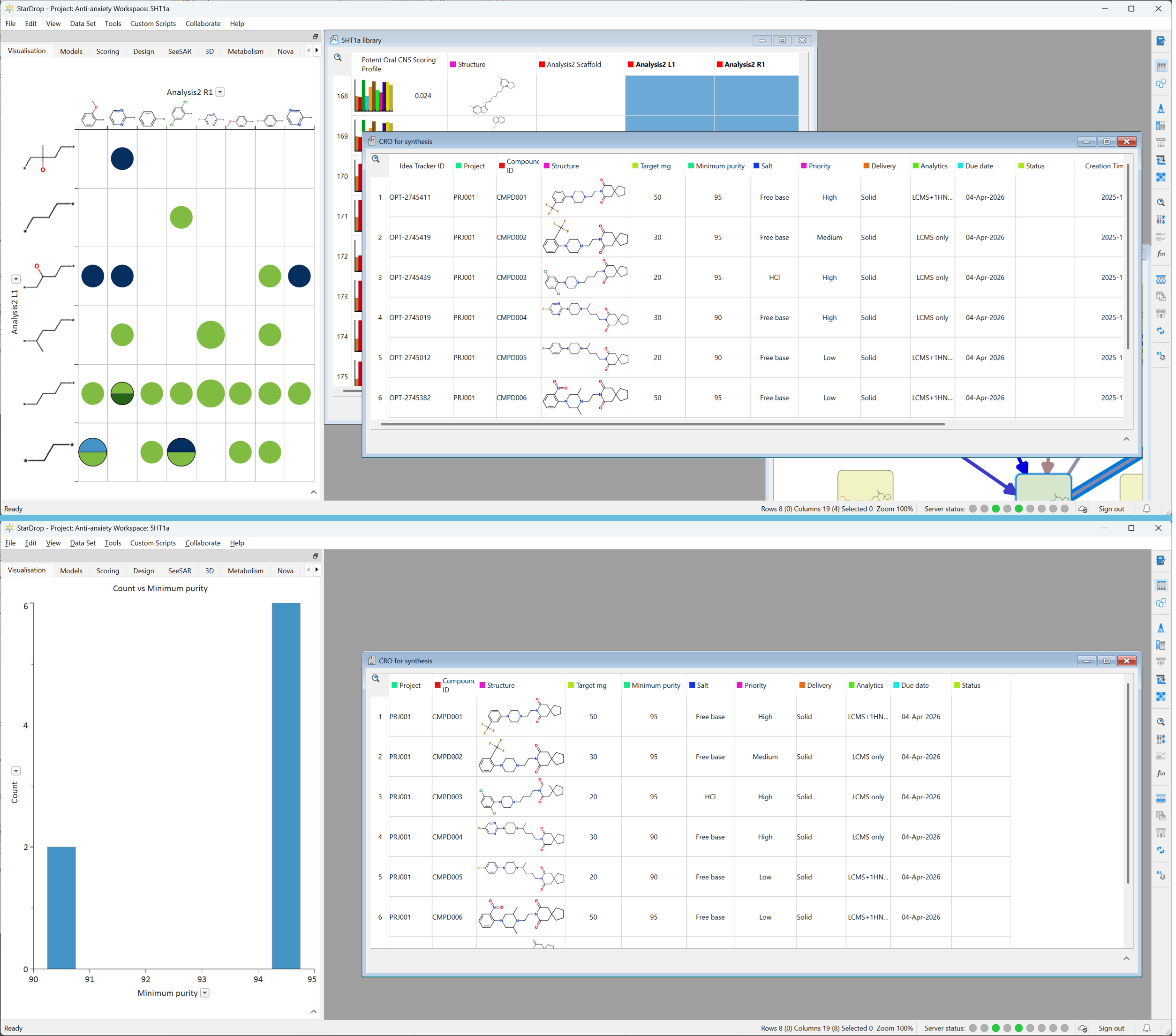
Top: Your scientists work with the master data set, that contains all projects compounds, all relevant data. and metadata about the compounds’ origin, any annotations, notes, or internal triage categories. Bottom: Your CRO will see a custom data subset, which contains only the information you choose for them in order to complete the work.
Data architecture: One master data set, one CRO data set
Inside the project, there are two parallel data sets to keep information cleanly separated.
Master data set (internal use only): Your scientists work with this data set. It contains all project compounds, all relevant assay data (refreshed automatically from corporate systems), all metadata about the compounds’ origin, any annotations, notes, or internal triage categories.
This data set is the full, authoritative view of the project.
The CRO data set: When you decide to send compounds to a CRO, creating a custom data subset is easy:
Copy selected structures and columns into the CRO data set
Grant invited users Viewer or Editor permissions to this subset as needed
This ensures that only fields intended for the CRO are included, and creates a clean, secure, external working set.
CRO execution in real-time
Your invited CRO partners will then work directly inside their own StarDrop workspace. This enables them to:
Review assigned structures
Design new structures, if part of their remit
Update synthesis status
Upload assay results
Add project-relevant observations
All updates will be instantly visible to your internal team directly in StarDrop, with no emails, spreadsheets or manual uploads required.
But crucially, CRO edits update only the CRO data subset, not the master data set.
Merging CRO results back into the internal workflow
When CRO results arrive, merging updates back into the master data set is simple.
Once you’ve reviewed any updates, you decide when to merge back into your master data set
During the merge, internal metadata is attached automatically – fields the CRO never saw
The master data set remains the single source of truth
This ensures confidentiality, auditability, and scientific integrity, without ever exposing sensitive information.
Collaboration without compromise
Modern drug discovery depends on collaboration beyond organisational boundaries. But collaboration should never compromise your data security or add data management bottlenecks.
StarDrop 8’s collaboration framework provides a practical solution: external partners work efficiently with the data they need, while internal teams maintain complete control over proprietary information and strategic context.
Ready to trial StarDrop?
Simply complete the form now for a free personalised demo and see how StarDrop fits your unique research needs.
Rae holds a PhD in Theoretical Chemistry from the University of Missouri-Columbia.
After 2 years at the helm of Optibrium’s super-star software development team, she made a lateral move within the organisation to focus more on planning and scoping the products and technologies of the future.
As Product Manager, she leverages over two decades of experience in software development, applications science, and business development—including valuable time spent as a customer. Rae serves as the crucial “universal translator,” adeptly converting customer requirements into technical specifications that enable our developers to deliver effective solutions to complex problems
The new Idea Tracker capability further improves the efficiency of drug discovery by supporting project management, idea sharing and molecule design tracking