Maximising the ROI of AI – A comprehensive evaluation of Cerella for drug discovery success
When evaluating any new technology, it is important to establish how you will validate whether it will deliver a return…

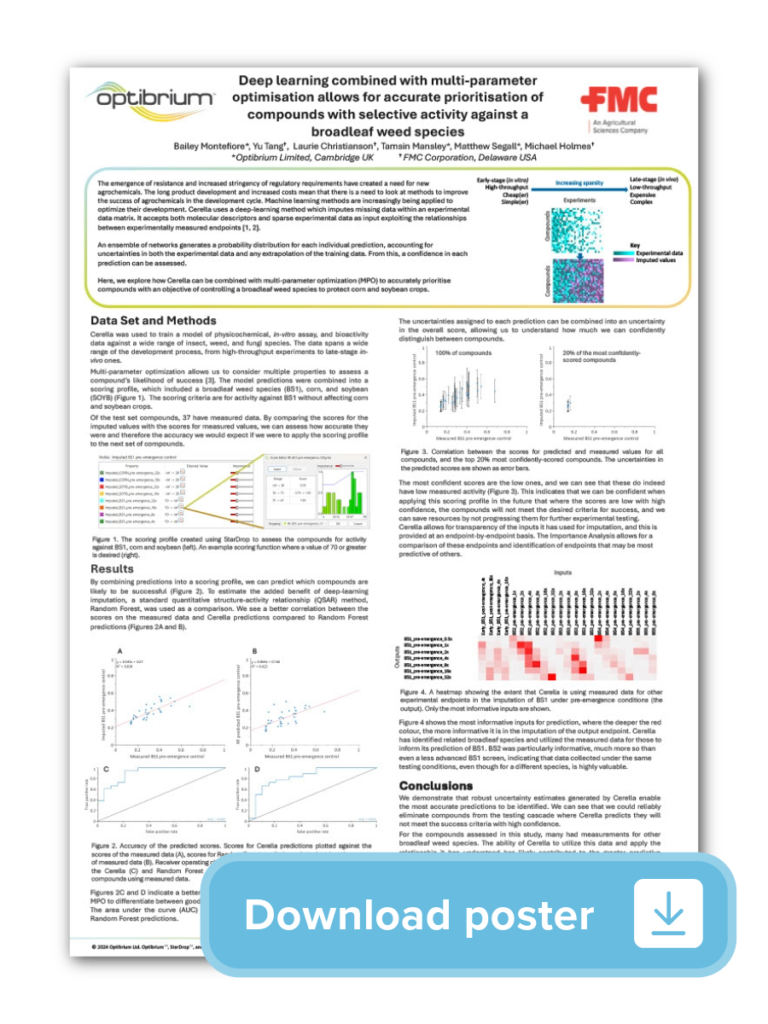
The agrochemical industry is facing growing challenges around resistance, stringent regulations, and pressures to reduce the time and cost of development. Teams are being asked to develop better active compounds faster and cheaper.
We recently presented a poster at SCI’s Innovation in Crop Protection, showing a case study using deep learning imputation to improve the accuracy in selecting active molecules. This allows agrochemical teams to make better resourcing decisions, by prioritising which molecules to submit to costly screening experiments.
You can view the full study here or download the poster pdf.
Selectivity was key in this project. Compounds needed to effectively control a broadleaf weeds species, while protecting corn and soybean crops. The need to balance multiple activities make compound optimisation a more complicated process.
In this work, we applied Cerella to train machine learning models on physicochemical properties, in vitro assay data, and bioactivity data spanning the development pipeline.
Unlike traditional QSAR methods that can struggle with sparse datasets, Cerella’s deep learning approach can handle missing data by learning the relationships between experimental endpoints.
We combined Cerella’s predictions with multi-parameter optimisation to create a comprehensive scoring profile. Our approach evaluated compounds across three dimensions: activity against the target broadleaf weed species, safety to corn crops, and safety to soybean crops.
This time-saving approach allows chemists to identify compounds that meet all success criteria simultaneously, rather than optimising individual properties in isolation.
When compared to Random Forest QSAR models, Cerella’s deep learning approach showed:
Additionally, Cerella’s most confident low-scoring predictions corresponded to genuinely poor experimental outcomes. This means teams can confidently deprioritise compounds will likely fail and avoid wasting valuable time and cost.
One interesting finding was Cerella’s ability to leverage data from related broadleaf species to predict activity against the target species. Related species data proved more informative than even preliminary screening data, highlighting the value of cross-species learning in this approach.
This machine learning approach using Cerella offers a way to reduce testing costs by eliminating poor compounds early with confidence. It enables better compound prioritisation through accurate predictions and mitigates risk through uncertainty-aware decision making.
When evaluating any new technology, it is important to establish how you will validate whether it will deliver a return…
OA paper outlining the practical applications of deep imputation on large-scale drug discovery data. It compares deep learning to traditional QSAR methods.

Ground truth matters more than algorithm hype In drug discovery, we deal in imperfect data. Assays are noisy. Endpoints are…
